Neste capítulo, vamos organizar um fluxo de trabalho mais próximo do que acontece em um projeto real. O problema escolhido será previsão de churn, isto é, estimar se um cliente tende a cancelar um serviço.
O foco aqui não é apenas treinar um modelo, mas estruturar o pensamento:
compreender o problema de negócio;
gerar ou organizar os dados;
separar treino e teste;
ajustar uma árvore interpretável;
avaliar o resultado;
extrair insight acionável.
8.1 Contexto do problema
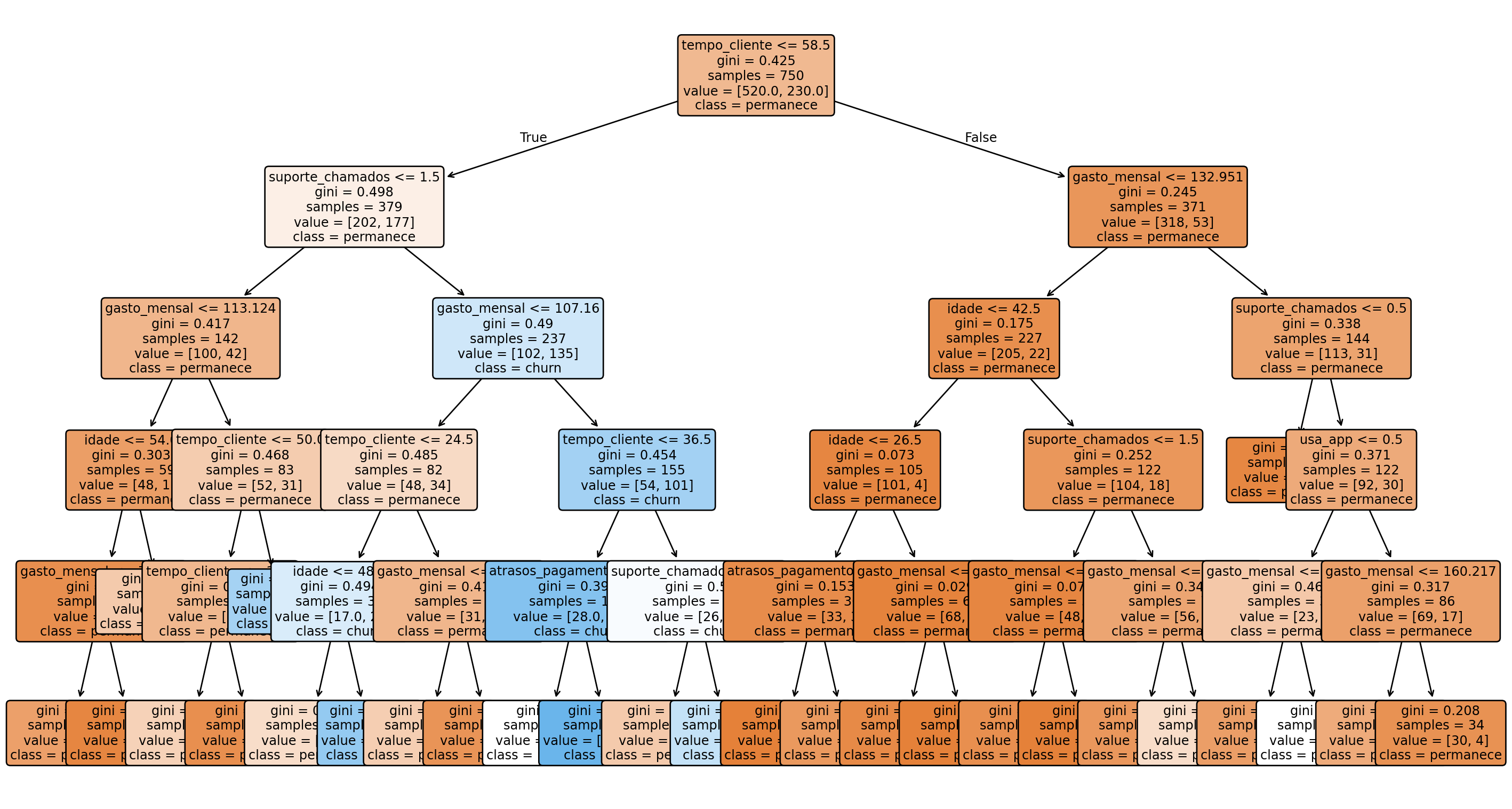
Em churn, geralmente queremos identificar clientes com maior risco de cancelamento para agir antes da perda acontecer. Uma árvore de decisão é particularmente útil nesse contexto porque transforma o problema em regras compreensíveis para equipes de negócio.
Esses hiperparâmetros foram escolhidos para equilibrar clareza e desempenho. Em problemas de negócio, uma árvore um pouco mais compacta pode ser mais útil do que uma estrutura enorme com pequenas vantagens marginais.
Se suporte_chamados e atrasos_pagamento aparecem no topo, isso sugere que experiência ruim e atrito operacional estão associados ao cancelamento. Se tempo_cliente tiver importância alta, o modelo pode estar distinguindo clientes ainda pouco fidelizados.
A comparação evidencia um ponto importante do livro inteiro: nem sempre a árvore mais complexa é a mais interessante.
8.9 Passo 8: validação de negócio
Em projetos reais, score não basta. É preciso verificar se as regras são acionáveis.
Exemplos de perguntas úteis:
clientes com muitos chamados estão recebendo suporte insuficiente?
atrasos em pagamento refletem dificuldade financeira ou falha operacional?
usuários que não usam o app estão menos engajados com o serviço?
clientes novos precisam de onboarding melhor?
8.10 Passo 9: possíveis ações práticas
Se a árvore identificar grupos de alto risco, algumas ações podem ser desenhadas:
campanha de retenção para clientes com alto gasto e muitos chamados;
oferta de suporte proativo para clientes novos;
automação de cobrança e regularização para perfis com atrasos;
incentivo ao uso do aplicativo para aumentar engajamento.
8.11 Passo 10: próximos refinamentos
Em um projeto real, poderíamos ainda:
usar validação cruzada para ajustar hiperparâmetros;
avaliar desbalanceamento de classes;
testar poda com ccp_alpha;
comparar com Random Forest e Gradient Boosting;
calibrar probabilidades, se necessário.
NotaResumo
Um estudo de caso mostra a árvore como ferramenta de previsão e de descoberta de regras.
A interpretabilidade ajuda a ligar score a ação de negócio.
Comparar uma árvore compacta com uma árvore livre é uma forma concreta de estudar complexidade.
O valor prático da árvore aumenta quando as regras se tornam acionáveis.
Este estudo de caso mostrou que uma árvore de decisão pode servir ao mesmo tempo como modelo preditivo e ferramenta de descoberta de regras. Em contextos empresariais, essa combinação é poderosa porque permite transformar previsões em ações concretas. No último capítulo, vamos consolidar o aprendizado com exercícios práticos.
AvisoErros comuns
focar apenas em score e ignorar a utilidade operacional das regras;
interpretar importância de atributo sem contexto de negócio;
construir uma árvore excessivamente detalhada para um público não técnico;
deixar de validar se a regra faz sentido fora da amostra sintética.
DicaPerguntas de revisão
Por que churn é um problema interessante para árvores de decisão?
O que uma variável importante sugere, e o que ela não prova?
Por que uma árvore mais simples pode ser mais útil para negócio?
Que tipo de ação prática pode surgir da leitura das regras?