Treinar um modelo é apenas parte do trabalho. Um modelo aparentemente bom pode estar apenas decorando o conjunto de treino. Avaliação adequada significa medir desempenho em dados não vistos e interpretar os resultados com critério.
5.1 Separação entre treino e teste
A primeira barreira contra o autoengano em machine learning é separar os dados em conjuntos distintos.
treino: usado para ajustar o modelo;
validação: usado para comparar configurações;
teste: usado para medir desempenho final de forma mais honesta.
No capítulo anterior usamos apenas treino e teste. Agora vamos ampliar essa avaliação.
5.2 Métricas para classificação
Em classificação, a acurácia é útil, mas não basta em todos os contextos.
Para entender essas métricas, usamos quatro quantidades da matriz de confusão:
TP (true positive): positivo previsto como positivo;
TN (true negative): negativo previsto como negativo;
FP (false positive): negativo previsto como positivo;
FN (false negative): positivo previsto como negativo.
É uma métrica geral e simples de comunicar, mas pode enganar em bases desbalanceadas. Se 95% dos exemplos forem da classe negativa, um modelo que quase sempre prevê “negativo” pode ter alta acurácia e ainda assim ser pouco útil.
5.2.2 Precision
Entre os exemplos previstos como positivos, quantos eram de fato positivos:
\[
Precision = \frac{TP}{TP + FP}
\]
Precision alta significa poucos falsos positivos. Ela é importante quando o custo de um alarme falso é alto, como em bloqueio indevido de transações legítimas.
5.2.3 Recall
Entre os exemplos realmente positivos, quantos foram encontrados:
\[
Recall = \frac{TP}{TP + FN}
\]
Recall alta significa poucos falsos negativos. Ela é essencial quando “deixar passar” um caso positivo é crítico, como triagem médica ou detecção de fraude.
O F1-score cresce quando há equilíbrio entre precision e recall e cai quando uma das duas é baixa. Por isso, é útil quando queremos uma visão única de desempenho em cenários com classes desbalanceadas ou com trade-off entre falsos positivos e falsos negativos.
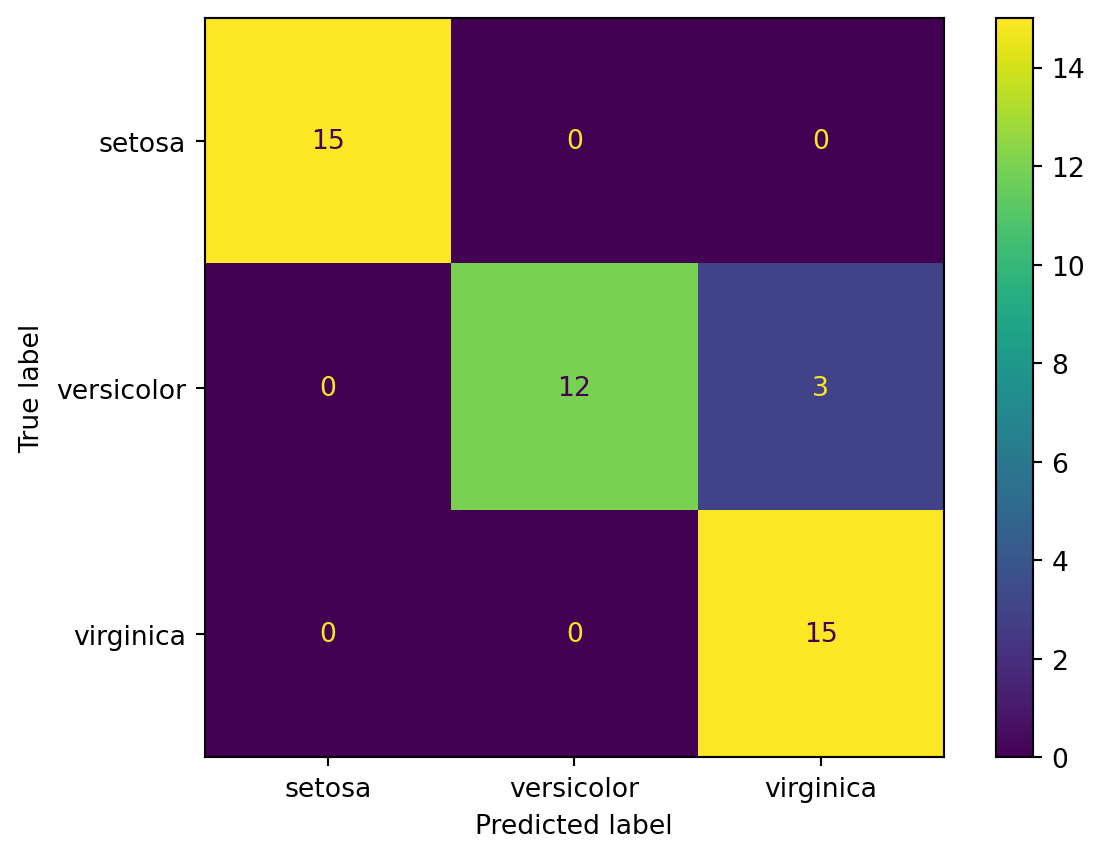
5.2.5 Matriz de confusão
Mostra com mais detalhe onde o modelo está acertando e errando.
Esse relatório é útil porque resume várias métricas por classe.
5.4 Por que validação cruzada importa
Uma única divisão treino-teste pode ser injusta com o modelo ou benevolente demais. A validação cruzada reduz essa dependência de uma partição específica.
Na validação cruzada k-fold, dividimos os dados em k partes. O modelo treina em k-1 partes e valida na parte restante. Repetimos isso k vezes, mudando o bloco de validação.
from sklearn.model_selection import cross_val_scorescores = cross_val_score( DecisionTreeClassifier(random_state=42), X, y, cv=5, scoring="accuracy")print("Scores:", scores)print("Média:", scores.mean())print("Desvio padrão:", scores.std())
Esse experimento ajuda a visualizar a relação entre simplicidade e desempenho.
NotaResumo
Avaliar bem é tão importante quanto treinar bem.
Validação cruzada reduz a dependência de uma única divisão treino-teste.
Grid search ajuda a explorar hiperparâmetros de forma sistemática.
O teste final deve ser preservado para avaliação honesta.
Avaliar bem uma árvore significa medir desempenho com honestidade, comparar configurações de maneira sistemática e interpretar os erros com atenção. No próximo capítulo, vamos aprofundar um dos riscos mais importantes desse modelo: o overfitting, e veremos como a poda ajuda a manter a árvore útil e interpretável.
AvisoErros comuns
usar o conjunto de teste para ajustar decisões repetidas vezes;
escolher modelo só pela acurácia;
ignorar variação entre folds;
confundir score alto no treino com capacidade de generalização.
DicaPerguntas de revisão
Qual é a diferença entre treino, validação e teste?
Quando a acurácia pode ser enganosa?
O que a validação cruzada ajuda a reduzir?
Por que o melhor modelo do grid deve ser avaliado depois no teste?