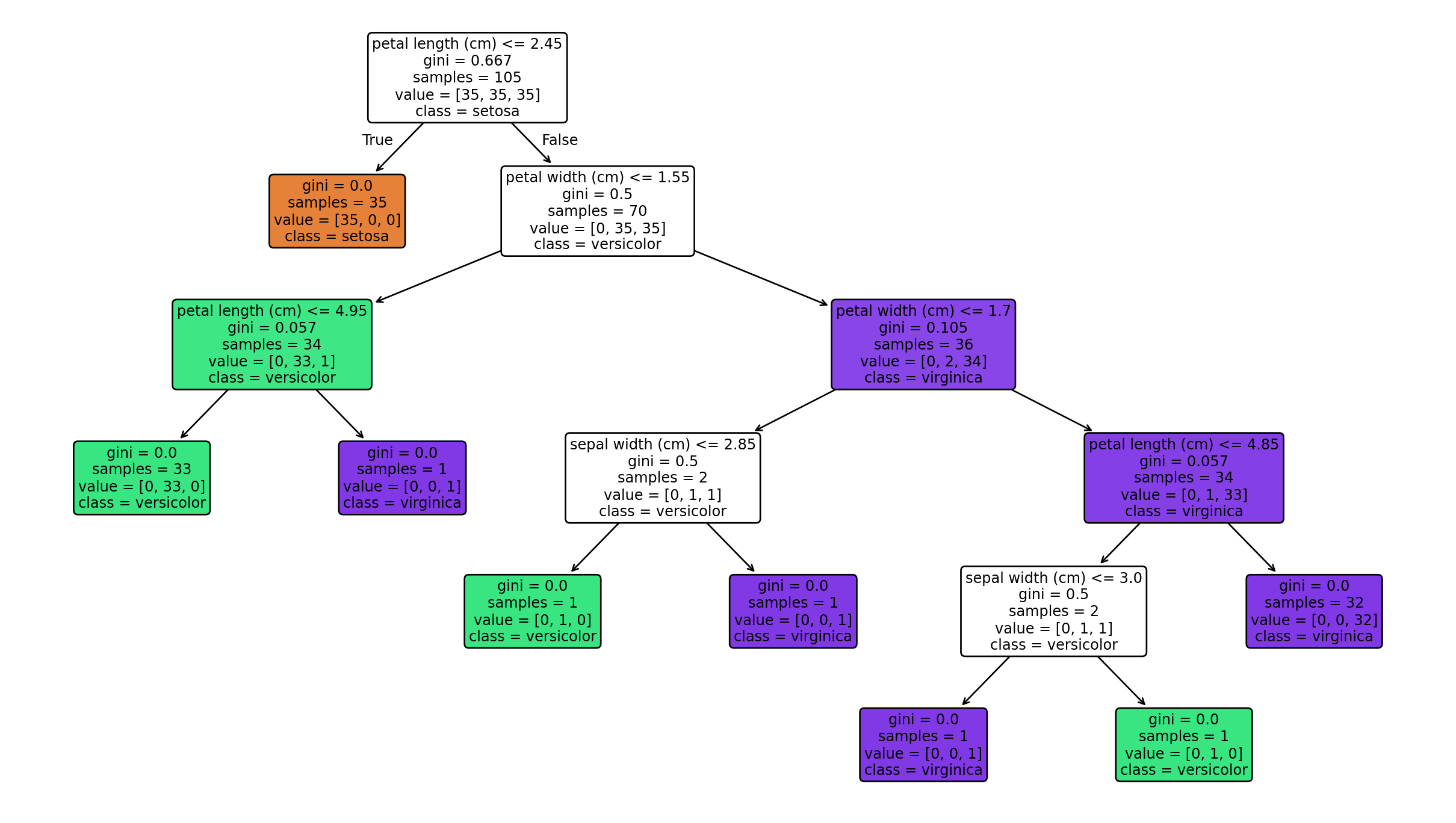
Neste capítulo, vamos sair da teoria e construir nossa primeira árvore de decisão com scikit-learn. O objetivo não é apenas treinar o modelo, mas observar como os conceitos de raiz, nós internos, folhas, impureza e profundidade aparecem concretamente.
4.1 Escolha do dataset
Vamos usar o conjunto Iris, um clássico da literatura de machine learning. Ele contém medidas de flores de três espécies diferentes e é excelente para demonstrar classificação supervisionada.
As variáveis de entrada são:
comprimento da sépala;
largura da sépala;
comprimento da pétala;
largura da pétala.
A variável alvo é a espécie da flor.
4.2 Preparando os dados
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import accuracy_score, classification_reportiris = load_iris()X, y = iris.data, iris.targetX_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=42, stratify=y)print("Formato de X:", X.shape)print("Classes:", iris.target_names)
Formato de X: (150, 4)
Classes: ['setosa' 'versicolor' 'virginica']
4.3 Treinando uma árvore inicial
model = DecisionTreeClassifier(random_state=42)model.fit(X_train, y_train)pred = model.predict(X_test)print("Acurácia:", accuracy_score(y_test, pred))print(classification_report(y_test, pred, target_names=iris.target_names))
Esse primeiro modelo já nos permite observar um ponto importante: árvores costumam se ajustar muito bem a datasets pequenos e estruturados, mas isso não significa automaticamente que vão generalizar bem em qualquer contexto.
4.4 O que a árvore aprendeu
Depois do treino, a árvore passa a ter uma estrutura interna com informações como:
a regra de divisão, como petal length (cm) <= 2.45;
a impureza do nó;
o número de amostras naquele ponto;
a distribuição das classes;
a classe majoritária prevista.
4.6 Interpretando a raiz
A raiz normalmente concentra a pergunta mais informativa de todo o problema. No Iris, é comum que medidas da pétala apareçam cedo na árvore, porque elas separam muito bem certas espécies.
Quando um atributo aparece perto da raiz, isso sugere que ele tem grande utilidade discriminativa para aquele conjunto de dados.
4.7 Medindo complexidade da árvore
Podemos inspecionar algumas propriedades do modelo.
print("Profundidade da árvore:", model.get_depth())print("Número de folhas:", model.get_n_leaves())
Profundidade da árvore: 5
Número de folhas: 8
Esses dois números ajudam a entender se a árvore está simples ou excessivamente detalhada.
4.8 Comparando uma árvore mais controlada
Uma boa prática é comparar o modelo livre com uma versão limitada.
Importância de atributo é útil, mas não deve ser lida como verdade absoluta. Ela depende da estrutura aprendida pela árvore e da forma como as variáveis competem entre si para entrar nas divisões.
Esse formato é excelente para documentação, ensino e discussão com pessoas que preferem texto a gráfico.
4.12 Boas práticas desde o primeiro modelo
Mesmo em exemplos simples, vale manter algumas disciplinas:
separar treino e teste;
fixar random_state para reprodutibilidade;
comparar versões mais simples e mais complexas;
olhar além da acurácia;
interpretar a árvore aprendida.
AvisoErros comuns
olhar apenas a acurácia e ignorar estrutura da árvore;
treinar sem separar treino e teste;
interpretar importância de atributos como causalidade;
assumir que a primeira árvore treinada já está pronta para uso final.
NotaResumo
O treino em Python materializa conceitos como raiz, profundidade e folhas.
A visualização da árvore ajuda a interpretar regras e cortes aprendidos.
Comparar uma árvore livre com uma árvore rasa é um bom hábito didático.
Importância de atributos e exportação textual ampliam a interpretabilidade.
Nosso primeiro modelo mostrou que árvores de decisão podem ser treinadas rapidamente e lidas com relativa facilidade. No entanto, ainda falta responder a perguntas importantes: como avaliar melhor a qualidade do modelo, como ajustar hiperparâmetros e como evitar que a árvore fique mais complexa do que o necessário. Esse será o foco do próximo capítulo.
DicaPerguntas de revisão
O que você observa em cada nó quando usa plot_tree?
Por que vale a pena comparar árvores com profundidades diferentes?
O que predict_proba adiciona a interpretação?
Em que situações export_text pode ser mais útil do que o gráfico?