Em julho de 2024, a Meta lançou um modelo de linguagem (LLM) open-source, o Llama-3.1-70B. Um pouco depois, em setembro a empresa NVIDIA lançou um derivado deste, o Llama 3.1-Nemotron-51B-Instruct. E em outubro lançou finalmente um modelo de 70b, o Llama 3.1 nemotron-70b-instruct.
O nemotron-70b performou melhor, em alguns testes comparativos, do que o GPT-4o. Nos testes, ele liderou em desempenho geral e também se destacou nas categorias chat (chat score) e raciocínio (reasoning score). Veja na Tabela 1 os dados comparativos com mais detalhes.
| Model | Overall Score | Chat Score | Reasoning Score |
|---|---|---|---|
| Llama 3.1 Nemotron-70B | 94.1 | 97.5 | 98.1 |
| Skywork-Reward-Gemma-2-27B | 93.8 | 95.8 | 96.1 |
| TextEval-Llama3.1-70B | 93.5 | 94.1 | 96.4 |
| GPT-4o | 86.7 | 96.1 | 86.6 |
Testes de uso
O Nemontron pode ser testado em build.nvidia.com, especificamente neste link. A inscrição concede acesso a 100.000 chamadas de API gratuitas. Além disso, ele está disponível para baixar no Hugging Face. Porém, haja poder de processamento para uma consulta local a este modelo em uma PC de mesa.
Realizei algumas consultas no site da NVIDIA (Figura 1) e a velocidade da resposta deixou muito a desejar em relação a quantidade de tokens por minuto. Um versão do Groq disponível no Groq Cloud (Figura 2), que usa uma versão também customizada do Llama, o llama3-groq-70b-8192-tool-use-preview, é muito mais veloz do que a disponibilizada no site da NVIDIA. Provavelmente isto está relacionado mais ao hardware da Groq, que parece ser mais eficiente, independente do modelo. Cabe ressaltar que a versão da NVIDIA deu uma resposta bem mais completa que a versão do Groq, para o mesmo prompt.
Figura 1 - Demonstração do Nemotron 70B no site da NVidia
Fonte: O Autor (2024)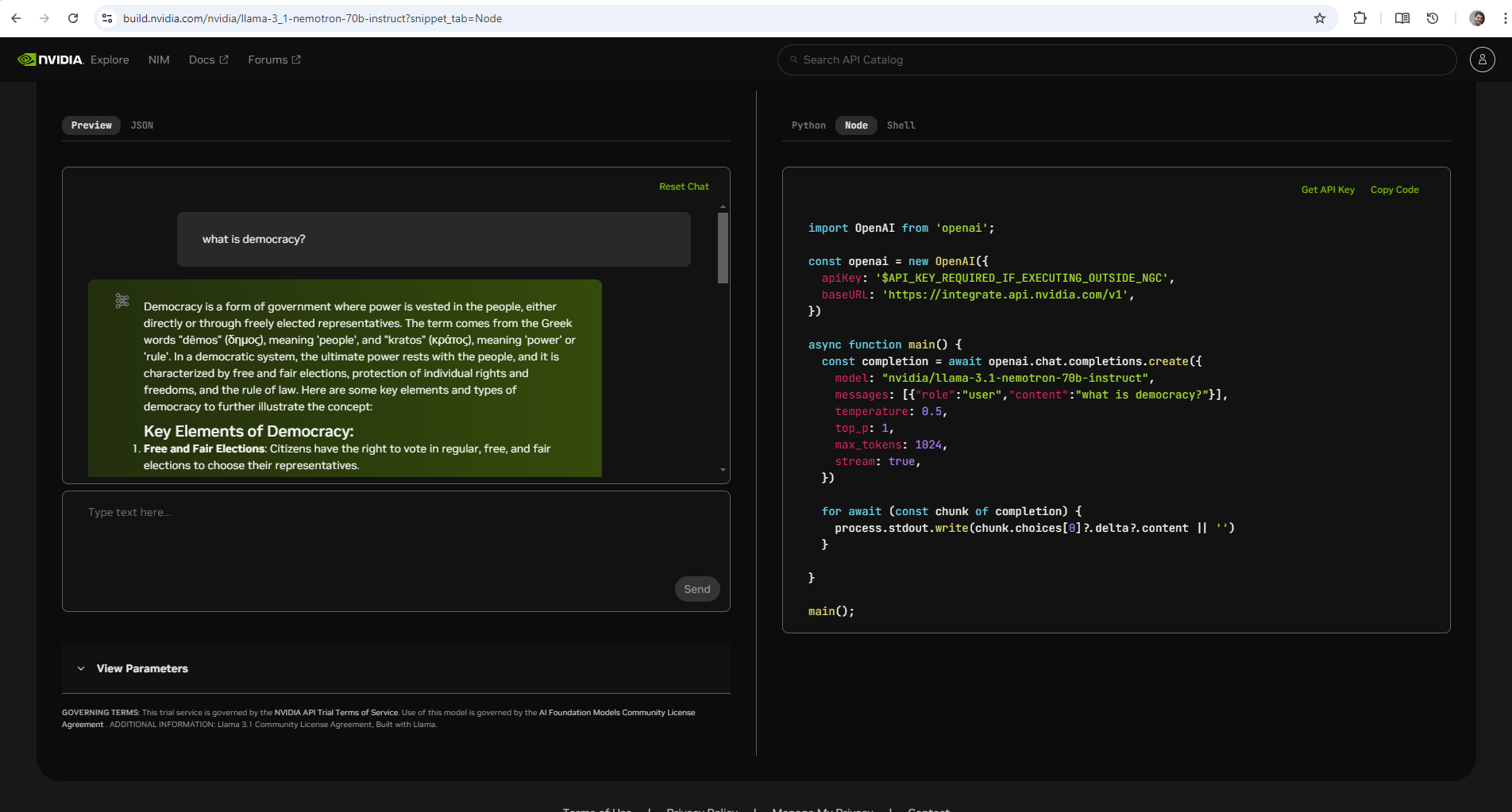
Figura 2 - Demonstração no Groq Cloud do modelo 70B tool use preview
Fonte: O Autor (2024)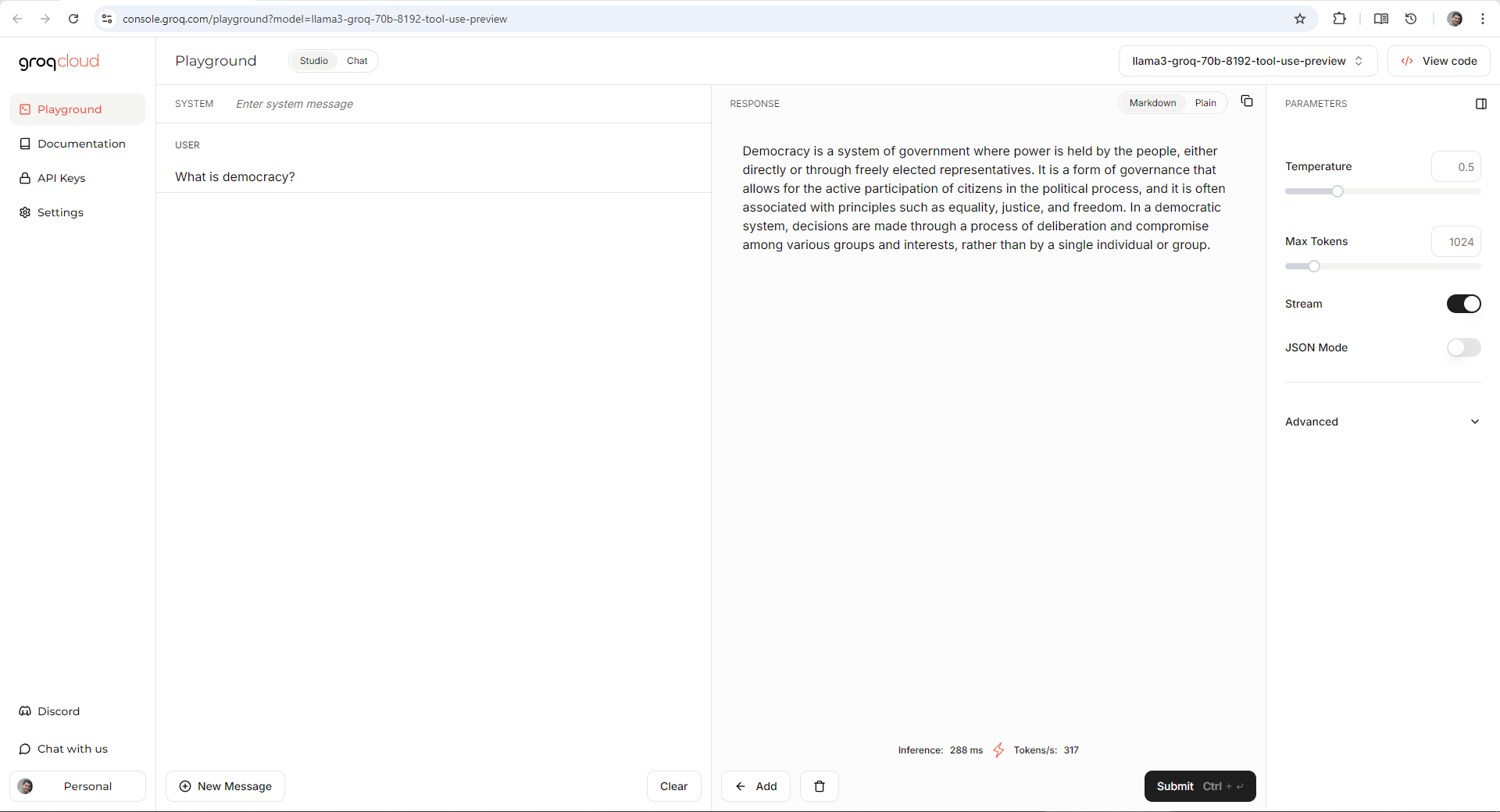
Arquitetura
Um LLM geralmente utiliza a arquitetura transformer, e no Nemotron não foi diferente. Esta arquitetura já é conhecida e permite que o modelo capture dependências de longo alcance no texto, tornando-o apto a compreender o contexto e a gerar respostas.
Outro recurso utilizado é o Attention Multi-Head que permite que o modelo se concentre em diferentes partes da entrada simultaneamente, aprimorando sua capacidade de compreender consultas complexas e produzir resultados diferenciados.
Por fim, foi implementado no modelo, a normalização de camadas. Ela ajuda a estabilizar o treinamento e a melhorar as taxas de convergência, resultando em um aprendizado mais rápido e eficiente. o modelo foi treinado em uma ampla gama de dados licenciados com a licença (CC-BY-4.0), que inclui livros, artigos e conteúdo da web. Ressaltando que o BY da licença exige que o crédito seja dado ao autor.
De acordo com a NVIDIA, o processo de treinamento do Llama 3.1 Nemotron-70B incluiu:
- aprendizagem supervisionada
- aprendizagem por reforço de feedback humano.
- Modelagem de recompensa: O modelo prevê a qualidade da resposta com base nas interações do usuário. Este mecanismo permite ajustar seus resultados de forma dinâmica, melhorando ao longo do tempo com base no feedback do mundo real.
Código
Em relação a código, a consulta ao modelo em python utiliza a mesma API do LLM da OpenAI (conforme pode ser visto no código abaixo), alterando somente a base url.
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = ""
)
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-70b-instruct",
messages=[{"role":"user","content":"What is machine learning?"}],
temperature=0.5,
top_p=1,
max_tokens=1024,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Curtiu? Deixei um comentário. Até o próximo post.
Referências
-Bind AI Blog post -CC-BY -GROQ -NVIDIA Blog post -Reddit post