flowchart TD
subgraph RNN_Flow [Fluxo RNN Sequencial]
direction LR
A[Input 1] --> H1[Hidden 1]
H1 --> H2[Hidden 2]
B[Input 2] --> H2
H2 --> H3[Hidden 3]
C[Input 3] --> H3
H3 --> O[Output]
end
style RNN_Flow fill:#f9f9f9,stroke:#333,stroke-width:2px
2 Introdução aos LLMs
Exploraremos a transição arquitetural que permitiu o surgimento de modelos como GPT e BERT, seguida de um guia para a configuração de um ambiente de desenvolvimento de alto desempenho com Python e PyTorch.
2.1 O Que São LLMs?
Neste livro, vamos destrinchar o funcionamento dos Large Language Models (LLMs), mergulhando nos detalhes da arquitetura Transformer e abrindo a ‘caixa-preta’ por trás dessas tecnologias.
Os Modelos de Linguagem de Grande Escala, conhecidos pela sigla em inglês LLM (Large Language Models), representam uma das conquistas mais impressionantes da inteligência artificial moderna. Trata-se de sistemas computacionais projetados para compreender, gerar e manipular texto em linguagem natural de maneira que se assemelha — e em muitos casos, ultrapassa — a capacidade humana de comunicação escrita.
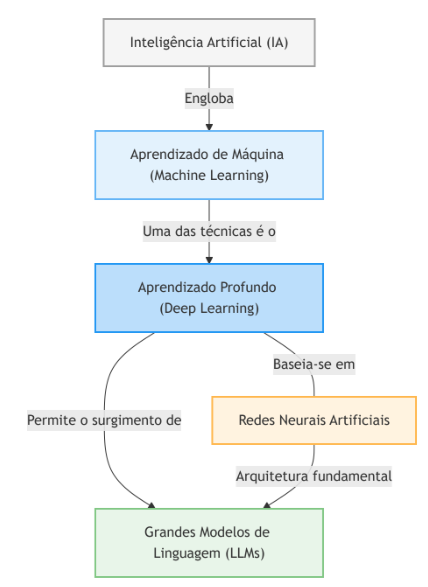
Um LLM é, fundamentalmente, um sistema matemático sofisticado que aprende padrões linguísticos a partir de vastas quantidades de texto. Diferentemente dos programas de computador tradicionais, que seguem instruções explícitas escritas por programadores, um LLM “aprende” a linguagem através da exposição massiva a exemplos de texto. Essa abordagem é comumente denominada aprendizado de máquina, ou machine learning, e mais especificamente, aprendizado profundo, ou deep learning, devido à utilização de redes neurais com múltiplas camadas.
A essência de um modelo de linguagem reside na sua capacidade de prever o que vem a seguir em uma sequência de texto. Quando você digita uma frase incompleta, o modelo é capaz de sugerir palavras ou construções que completem o pensamento de forma coerente. Essa habilidade de previsão probabilística é o fundamento sobre o qual toda a arquitetura dos LLMs foi construída.
2.2 O que são Redes Neurais
Nas últimas décadas, sistemas avançados de inteligência artificial — como modelos de tradução automática, reconhecimento de imagens e geração de texto e os próprios LLMs — passaram a ser dominados por uma classe específica de técnicas conhecida como aprendizado profundo (deep learning). Embora o termo possa sugerir algo excessivamente complexo ou obscuro, sua base conceitual é relativamente direta: trata-se do uso sistemático de redes neurais artificiais para aproximar funções complexas a partir de dados. Veja na figura abaixo:
Em ciência da computação clássica, estamos acostumados a resolver problemas explicitando regras e algoritmos: fornecemos uma função bem definida e esperamos que ela produza a saída correta para qualquer entrada válida. Entretanto, muitos problemas relevantes do mundo real não admitem uma formulação algorítmica exata. Nesses casos, o que temos não é a função em si, mas apenas exemplos do seu comportamento. Redes neurais surgem exatamente como um mecanismo matemático para lidar com esse cenário.
Historicamente, a ideia de redes neurais remonta a 1944, com o trabalho seminal de Warren McCullough e Walter Pitts, que propuseram um modelo matemático simplificado de neurônios biológicos. Desde então, a área passou por ciclos de entusiasmo e frustração. O que explica seu sucesso contemporâneo não é uma mudança conceitual radical, mas a convergência de três fatores: disponibilidade massiva de dados, avanços em métodos de otimização e aumento expressivo do poder computacional, especialmente com o uso de GPUs.
Do ponto de vista funcional, uma rede neural pode ser entendida como um aproximador universal de funções. Dado um conjunto suficientemente grande de exemplos representativos, a rede é capaz de aprender uma função que mapeia entradas em saídas com erro controlado. Esse é o motivo pelo qual ela pode, por exemplo, estimar a probabilidade de um tumor ser maligno a partir de exames clínicos, mesmo sem existir uma equação fechada que descreva tal decisão.
A estrutura interna de uma rede neural é organizada em camadas compostas por unidades chamadas neurônios artificiais. Cada neurônio executa uma operação matemática elementar: recebe um conjunto de valores de entrada, multiplica cada um por um peso associado, soma esses produtos e adiciona um termo constante denominado viés (bias). O resultado dessa soma é então transformado por uma função de ativação.
A função de ativação desempenha um papel conceitualmente crucial. Sem ela, toda a rede se reduziria a uma única transformação linear, independentemente do número de camadas. Ao introduzir não linearidade, funções como ReLU, sigmoide ou tanh permitem que a rede represente relações altamente complexas entre variáveis. Em termos intuitivos, a função de ativação decide quais sinais devem ser propagados adiante e quais devem ser atenuados ou descartados.
A maioria das arquiteturas clássicas de redes neurais é do tipo feed-forward, no qual a informação flui apenas no sentido da entrada para a saída, sem ciclos. Os dados atravessam sucessivamente as camadas, sendo transformados passo a passo, até que a última camada produza a saída final do modelo. Essa saída pode representar uma classe, um valor contínuo ou mesmo uma distribuição de probabilidades, dependendo do problema.
O processo de aprendizado consiste em ajustar iterativamente os pesos e vieses da rede. Inicialmente, esses parâmetros são definidos com valores aleatórios. A rede então produz uma saída para cada exemplo de treinamento, que é comparada com a saída correta esperada. A diferença entre essas duas quantidades é quantificada por uma função de perda (loss), que mede o quão distante o modelo está do comportamento desejado.
A partir dessa perda, algoritmos de otimização — como o gradiente descendente e suas variantes — ajustam os parâmetros da rede de forma a reduzir progressivamente o erro. Em termos conceituais, o treinamento pode ser visto como uma busca em um espaço de altíssima dimensionalidade por uma configuração de parâmetros que minimize a perda média sobre os dados de treinamento, mantendo capacidade de generalização.
Essa perspectiva permite desmistificar redes neurais. Elas não “pensam” nem “entendem” no sentido humano, mas implementam um mecanismo matemático elegante para capturar regularidades estatísticas em dados. Sua força reside menos em cada neurônio individual e mais no comportamento coletivo emergente de milhares ou milhões dessas unidades trabalhando em conjunto.
É importante enfatizar que esse arcabouço conceitual serve como base para arquiteturas mais sofisticadas, como redes convolucionais, recorrentes e modelos baseados em atenção. Contudo, todas essas variações compartilham o mesmo princípio fundamental aqui descrito: aprender uma função complexa a partir de exemplos por meio de composições sucessivas de transformações simples.
2.3 A Escala dos Modelos Modernos de LLM
Nos modelos de linguagem grande (em inglês Large Language Model), o termo “grande” não é meramente decorativo. Estes modelos são chamados assim porque foram treinados com quantidades massivas de dados textuais e possuem bilhões ou até trilhões de parâmetros ajustáveis. Um parâmetro, neste contexto, é um valor numérico que o modelo aprende durante o treinamento e que determina como ele processa e transforma a informação.
Para entender a magnitude envolvida, considere que modelos como o GPT-4, Claude, Gemini e Llama possuem centenas de bilhões ou até trilhões de parâmetros. Cada parâmetro é uma pequena variável matemática que, em conjunto com todos os outros, permite ao modelo capturar as complexidades intrincadas da linguagem humana. A escala desses modelos é um dos fatores principais que lhes confere a capacidade de gerar texto coerente, contextualizado e surpreendentemente natural.
2.4 Por Que LLMs São Importantes
A relevância dos modelos de linguagem de grande escala transcende o mero fascínio tecnológico. Eles representam uma mudança na forma como humanos e máquinas interagem. Antes dos LLMs, a comunicação com computadores exigia que os humanos aprendessem linguagens de programação ou interfaces específicas. Com os LLMs, a linguagem natural torna-se o meio primário de comunicação, democratizando o acesso à informação e à automação.
Esses modelos têm aplicações que abrangem praticamente todos os setores da atividade humana. Na medicina, auxiliam no diagnóstico e na pesquisa científica. Na educação, funcionam como tutores personalizados. Na escrita criativa, servem como colaboradores e fontes de inspiração. No atendimento ao cliente, operam como assistentes disponíveis vinte e quatro horas por dia. A versatilidade dos LLMs é uma consequência direta da generalidade do problema que eles resolvem: entender e gerar linguagem.
2.5 A Evolução do Processamento de Linguagem Natural (PLN)
2.5.1 Os Primórdios: Modelos Estatísticos de Linguagem
Para compreender a revolução representada pelos LLMs modernos, é instrutivo recuar no tempo e examinar as abordagens que os precederam. Nas décadas de 1980 e 1990, os modelos de linguagem eram predominantemente estatísticos. Modelos como os n-gramas dominavam o campo, onde a probabilidade de uma palavra aparecer era calculada com base nas n palavras anteriores.
Esses modelos estatísticos tinham limitações severas. Quanto maior o valor de n necessário para capturar contexto relevante, maior a quantidade de dados necessária para estimar todas as combinações possíveis. A maldição da dimensionalidade tornava impossível capturar dependências de longo alcance de forma eficiente. Além disso, esses modelos não conseguiam generalizar para sequências nunca vistas no treinamento,pois eram essencialmente tabelas de lookup probabilístico.
2.5.2 A Era das Redes Neurais Recorrentes
O salto seguinte veio com a introdução das redes neurais recorrentes (RNNs), especialmente as Long Short-Term Memory (LSTM) e Gated Recurrent Units (GRUs). Essas arquiteturas foram capazes de superar as limitações dos n-gramas ao aprender representações densas e contínuas de palavras, os chamados embeddings, e ao processar sequências de forma sequencial, mantendo um estado interno que capturava informação contextual.
As RNNs permitiram, pela primeira vez, que modelos de linguagem capturassem dependências de longo prazo em textos. Uma RNN pode, em teoria, “lembrar” de informações vistas centenas de passos atrás na sequência. Na prática, no entanto, as RNNs sofriam de problemas de vanishing gradients (gradientes que desaparecem durante o treinamento), que dificultavam o aprendizado de dependências muito longas.
- Processamento Sequencial: As RNNs processam palavras uma de cada vez, em uma ordem estrita (da esquerda para a direita). O hidden state (estado oculto) do passo \(t\) depende da entrada atual e do estado oculto do passo \(t-1\).
- O Gargalo (Bottleneck): Impossibilidade de Paralelização: Como o cálculo do passo \(t\) requer o resultado de \(t-1\), não é possível utilizar massivamente o paralelismo das GPUs modernas. Esquecimento de Longo Prazo: Mesmo com LSTMs, o contexto se dilui em sequências muito longas. O modelo “esquece” o início da frase quando chega ao final.
2.5.3 A Revolução Transformer
Em 2017, um artigo acadêmico intitulado “Attention Is All You Need”, escrito por pesquisadores do Google e da Universidade de Toronto, apresentou uma arquitetura que transformaria irreversivelmente o campo da processamento de linguagem natural. O Transformer, como foi denominado, abandonou completamente a ideia de processamento sequencial em favor de um mecanismo denominado auto-atenção, ou self-attention.
O artigo demonstrou que, utilizando exclusivamente mecanismos de atenção, era possível alcançar resultados superiores aos das arquiteturas baseadas em recorrência, com a vantagem adicional de ser altamente paralelizável, permitindo treinamento em hardware gráfico (GPUs) e tensores (TPUs) de forma muito mais eficiente. Portanto, a história moderna do PLN pode ser dividida em duas eras principais: a era pré-Transformer (dominada por redes recorrentes) e a era pós-Transformer (dominada por mecanismos de atenção).
A arquitetura Transformer descartou a recorrência em favor do mecanismo defice Self-Attention (Autoatenção).
- Paralelização Total: O Transformer processa toda a sequência de entrada simultaneamente, não sequencialmente.
- Mecanismo de Atenção: Permite que o modelo “olhe” para todas as outras palavras na frase ao mesmo tempo para entender o contexto de uma palavra específica, independentemente da distância entre elas.
- Positional Encoding: Como não há recorrência, a ordem das palavras é injetada matematicamente através de vetores de posição.
Após o artigo seminal de 2017, uma nova classe de modelos emergiu: os modelos generativos pré-treinados, conhecidos pela sigla GPT (Generative Pre-trained Transformer). O primeiro GPT, apresentado pela OpenAI em 2018, demonstrou que era possível pré-treinar um modelo de linguagem em grandes volumes de texto não supervisionado e, em seguida, refiná-lo (fine-tunar) para tarefas específicas com relativamente poucos exemplos.
Essa abordagem de pré-treinamento seguido de refinamento tornou-se o paradigma dominante e inaugurou uma era de escalabilidade sem precedentes. Cada geração de modelos trouxe aumentos exponenciais no número de parâmetros e na quantidade de dados de treinamento, resultando em capacidades cada vez mais impressionantes.
2.5.4 Diagrama de Evolução e Arquitetura
O diagrama abaixo ilustra o fluxo completo de um modelo de linguagem N-gramas, desde a fase de treinamento até a fase de inferência (previsão/geração de texto)
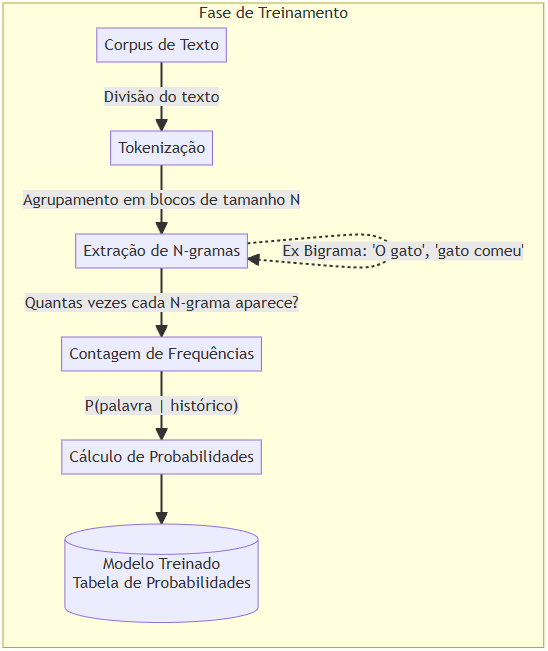
O diagrama acima tem duas fases
Fase de Treinamento:
- Recebe um volume de textos brutos (Corpus).
- Divide-os em pedaços básicos (Tokens).
- Agrupa esses tokens no tamanho desejado, por exemplo, de 2 em 2 para um modelo Bigrama (Extração de N-gramas).
- Conta as repetições e gera probabilidades estatísticas para saber “qual palavra é mais provável de aparecer depois de X” (Cálculo de Probabilidades).
Fase de Inferência / Geração:
- Para gerar um texto ou fazer o autocompletar, o modelo pega a frase atual (Contexto).
- Olha apenas para as palavras anteriores restritas ao tamanho do N-grama (Extração do Histórico).
- Consulta a sua “Tabela Mágica” (Busca no Modelo).
- Cospe a palavra que estatisticamente faz mais sentido a seguir (Previsão)
O diagrama abaixo ilustra o processamento linear de uma Rede Neural Recorrente (RNN).
No diagrama acima é possível visualizar o “Gargalo” destas redes.
O diagrama flui da esquerda para a direita , representando o tempo passando enquanto o modelo lê uma frase, palavra por palavra:
Entradas (Inputs 1, 2 e 3): Representam os tokens da sua sequência sendo inseridos um por vez. Por exemplo, em uma frase como “O gato dormiu”, Input 1 seria “O”, Input 2 seria “gato”, etc.
Estados Ocultos (Hidden 1, 2 e 3): Esta é a “memória” de curto prazo da rede. Ela acumula o conhecimento do que já foi lido.
Quando o Input 1 entra, ele gera o estado Hidden 1.
Quando o Input 2 entra, observe que há duas setas apontando para Hidden 2: uma vindo do Input 2 e outra vindo do Hidden 1. Isso significa que o modelo processa a palavra atual combinada com a “lembrança” da palavra anterior.
O Hidden 3 faz o mesmo, dependendo do Input 3 e de toda a memória acumulada lá atrás no passo do Hidden 2.
Saída (Output): No final da cadeia, o estado oculto final (Hidden 3) possui (em teoria) o contexto encapsulado de toda a sequência lida, e é usado para gerar o resultado final, como prever a próxima palavra.
O diagrama serve visualmente para provar o gargalo de processamento: a impossibilidade de paralelização.
Fica evidente graças às setas conectando os sucessivos nós Hidden que você não pode calcular matematicamente o bloco Hidden 3 sem antes ter terminado de calcular o bloco Hidden 2, que precisa do bloco Hidden 1.
Computadores modernos e Placas de Vídeo (GPUs) são extremamente rápidos e construídos para processar milhares de coisas ao mesmo tempo (“em paralelo”). No entanto, essa técnica quebra esse poder, pois força a máquina a esperar pacientemente o passo anterior terminar (fila indiana).
flowchart TD
subgraph Transformer_Flow [Fluxo Transformer GPT]
direction TB
Input[Input Sequence: Palavra 1, 2, 3...] --> Embed[Embeddings + Positional Encoding]
Embed --> MHA[Multi-Head Self-Attention]
MHA --> Norm1[Add & Norm]
Norm1 --> FF[Feed Forward Network]
FF --> Norm2[Add & Norm]
Norm2 --> Out[Output Probabilities]
end
style Transformer_Flow fill:#e1f5fe,stroke:#333,stroke-width:2px
2.6 Tipos de LLMs Baseados em Transformers e Causal Language Modeling (CLM)
Os LLMs modernos geralmente utilizam variações da arquitetura Transformer original:
- Encoder-Only (ex: BERT): Especialistas em “entender” o texto. Ótimos para classificação, reconhecimento de entidades e análise de sentimento. O modelo vê o contexto bidirecional (esquerda e direita).
- Decoder-Only (ex: GPT, LLaMA): Especialistas em “gerar” texto. Treinados para prever a próxima palavra (causal language modeling). O modelo vê apenas o contexto à esquerda.
- Encoder-Decoder (ex: T5, BART): Utilizados para tradução e resumo, onde uma sequência é transformada em outra.
Causal Language Modeling (CLM) é o objetivo de treinamento em que o modelo aprende a prever o próximo token de uma sequência, usando apenas os tokens anteriores como contexto.
Em termos simples, dado um texto como:
Eu gosto de estudar
o modelo aprende algo como:
- depois de
Eu→ prevergosto - depois de
Eu gosto→ preverde - depois de
Eu gosto de→ preverestudar
Ou seja, ele sempre prevê da esquerda para a direita.
A palavra causal aqui não significa “causa” no sentido filosófico. Significa que o modelo respeita uma máscara causal: ao prever o token atual, ele não pode olhar para o futuro. Ele só enxerga os tokens anteriores.
Formalmente, para uma sequência (x_1, x_2, …, x_T), o CLM maximiza a probabilidade:
\[ P(x_1, x_2, ..., x_T) = \prod_{t=1}^{T} P(x_t \mid x_{<t}) \]
Isso quer dizer que a probabilidade da sequência inteira é decomposta como uma cadeia de previsões do próximo token.
Durante o treinamento, normalmente usa-se teacher forcing: a sequência correta é dada ao modelo, e ele tenta prever cada próximo token. A perda costuma ser cross-entropy entre a distribuição prevista e o token verdadeiro seguinte.
Exemplo com deslocamento:
- Entrada:
O gato dorme
- Alvo:
gato dorme <eos>
Então o modelo recebe a frase deslocada e aprende a prever o próximo elemento em cada posição.
Esse objetivo é típico de modelos autoregressivos, tais como GPT, LLaMA, Mistral, Gemma e semelhantes.
Ele é diferente de objetivos como o Masked Language Modeling (MLM), usado em BERT, onde alguns tokens são mascarados e o modelo tenta recuperá-los usando contexto dos dois lados.
Na prática, o CLM é muito adequado para geração de texto, autocompletar, chatbots, resumo generativo, - tradução autoregressiva, geração de código e outras tarefas de PLN.
A principal intuição é: o modelo aprende a continuar sequências plausíveis.
Exemplo em pseudoformato:
Sequência: [Eu] [gosto] [de] [Python]
Passos de treino:
entrada: [Eu] alvo: [gosto]
entrada: [Eu gosto] alvo: [de]
entrada: [Eu gosto de] alvo: [Python]
NoteResumo
Compreendemos que a limitação de processamento sequencial das RNNs levou ao desenvolvimento dos Transformers, que utilizam mecanismos de atenção e processamento paralelo.